Parser combinators are a powerful and elegant technique for constructing parsers, in a modular and reusable way. This article series will introduce you the concept of parser combinators and guide you through building your own parser combinator micro-library and using it to define complex parsers in a declarative manner. Some familiarity with functional programming concepts and knowledge of what a monad is will be helpful, but not strictly necessary.
Typescript will be the language of choice for code snippets due to its reach. It’s surprisingly well suited for building parsers, thanks to discriminated unions and generics, but if you’re familiar with Rust or a functional programming language, you’ll have no trouble following along.
Acknowledgments#
My first encounter with parser combinators was through this incomplete article series, that I read a few years ago: How to write your own JSON parser using functional TypeScript & fp-ts - part I. It not only helped me pass the Formal Languages and Automata Theory course at university, but also made the whole experience very enjoyable. I hope that this article series will have a similar effect on your programming journey!
Parsing and Grammars#
Before getting into parser combinators and any code, let’s briefly discuss what parsing is and what are the traditional approaches to it.
Parsing is the process of analyzing a sequence of symbols (like characters in a string) to determine it’s structure according to a given formal grammar. The most common use case for parsing is to analyze the structure of code written in a programming or domain specific language to convert it into a structured representation (AST) that can be further processed by a compiler or interpreter, but parsing is also used in many other domains, such as date/time parsing, data deserialization (e.g., JSON, YAML), custom encoding schemes and more. It’s very likely that you’ll have the opportunity to write a parser at some point, even if you’re not working on a compiler or interpreter.
Grammar classification#
Before writing a parser, it’s important to understand the grammar of the language you’re trying to parse. A grammar defines the rules and structure of the language, specifying how valid sentences can be formed. Those come in 4 main types, based on their expressive power (and parsing complexity), defined by the Chomsky hierarchy:

- Type 3: Regular Grammars - The simplest type of grammar, which can be recognized by finite automata. Regular expressions are a common way to define regular grammars. They are suitable for simple languages, such as lexical analysis (tokenization) in compilers. An example of a regular language would be a string that can either be an ISO format date-only, or an ISO format date-time in UTC (e.g.,
2023-10-15or2023-10-15T13:45:30Z).
Regex representation:
/^\d{4}-\d{2}-\d{2}(T\d{2}:\d{2}:\d{2}Z)?$/ABNF representation:
; Core Rules
DIGIT = %x30-39
; Date Components
year = 4DIGIT
month = ("0" %x31-39) / ("1" %x30-32) ; 01-12
day = ("0" %x31-39) / (%x31-32 DIGIT) / "30" / "31" ; 01-31
; Time Components
hour = (%x30-31 DIGIT) / "2" %x30-33 ; 00-23
minute = %x30-35 DIGIT ; 00-59
second = %x30-35 DIGIT ; 00-59
; ISO Date (YYYY-MM-DD)
date-only = year "-" month "-" day
; ISO Date-Time UTC (YYYY-MM-DDTHH:MM:SSZ)
date-time-utc = date-only "T" hour ":" minute ":" second "Z"
; Final Rule
iso-date-string = date-only / date-time-utcType 2: Context-Free Grammars - More powerful than regular grammars, context-free grammars can be recognized by pushdown automata. They are suitable for defining the syntax of (some) programming languages, as they can handle nested structures and recursive patterns. An example of a context-free language would be balanced parentheses, such as
(),(()), or(()()). JSON is a context-free language as well, which we’ll implement a parser for later in this article series.Type 1: Context-Sensitive Grammars - Even more powerful, context-sensitive grammars can be recognized by linear-bounded automata. They can express languages that require context for proper parsing, which means that the same sequence of symbols can have different meanings based on the preceding or following symbols (context). Examples:
- Javascript: While most of Javascript’s syntax can be described using context-free grammars, some constructs require context-sensitive parsing. For instance, the
/symbol can either mean division or the start of a regular expression, depending on the context. - HTML: HTML is another example of a context-sensitive language, since closing tags (e.g.,
</div>) must match their corresponding opening tags (<div>), which requires context to ensure proper nesting and structure. You might find this infamous Stack Overflow answer more amusing after learning about this classification.
- Javascript: While most of Javascript’s syntax can be described using context-free grammars, some constructs require context-sensitive parsing. For instance, the
Type 0: Unrestricted Grammars - The most general type of grammar, unrestricted grammars can be recognized by Turing machines. These grammars can use recursive rules and it’s not guaranteed that a parser will terminate for all inputs. Giving a practical example of a type 0 grammar is difficult, but macro systems in programming languages can exhibit type 0 grammar characteristics.
Parser combinators are typically used to implement parsers for context-free grammars (Type 2), but, although non-idiomatic, they can be adapted to parse context-sensitive grammars (Type 1) as well.
The parsing pipeline#
When referring to programming languages, parsing is usually a part of a larger compilation or interpretation pipeline. The typical stages of this pipeline are:
Source Code -> Lexical Analysis (Tokenization) -> Syntax Analysis (Parsing) -> Interpretation/CompilationEach stage might consist of multiple sub-stages, such as semantic analysis after parsing or optimization before code generation in a compiler.
While it’s not strictly necessary to do so, parser combinators combine the tokenization and parsing stages into a process, called scannerless parsing.
Implementing a simple parser#
We’ll start the code implementation by defining the inputs and outputs of our parsers.
type Input = {
text: string;
index: number;
};
type ParseResult<T> =
| { success: true; value: T; remaining: Input }
| { success: false };The index field will be used to track how many characters have been consumed by a given parser.
The parser itself will have the following structure:
class P<T> {
constructor(private parseFn: (input: Input) => ParseResult<T>) {}
parse(inputText: string): ParseResult<T> {
const input: Input = { text: inputText, index: 0 };
return this.parseFn(input);
}
private run(input: Input): ParseResult<T> {
return this.parseFn(input);
}
}The name P is short for “Parser” (duh), but since we’ll use it a lot, it’s convenient to have a short name for it.
The building blocks#
At its core, a parser combinator is a combinator of multiple smaller parsers. That means we must have some fundamental building blocks, for both parsers and combinators.
The simplest parsers we can define would be for a single character and for a single string:
class P<T> {
static char<C extends string>(c: C): P<C> {
return new P<C>((input) => {
if (input.index < input.text.length && input.text[input.index] === c) {
return {
success: true,
value: c,
remaining: { text: input.text, index: input.index + 1 },
};
}
return { success: false };
});
}
static string<S extends string>(str: S): P<S> {
return new P<S>((input) => {
if (input.text.slice(input.index, input.index + str.length) === str) {
return {
success: true,
value: str,
remaining: { text: input.text, index: input.index + str.length },
};
}
return { success: false };
});
}
}By itself, those parsers are not very useful. Let’s define some simple combinators to combine them into more complex parsers. The first combinator we’ll implement is or, which tries the first parser, and if it fails, tries the second one:
class P<T> {
or<U>(other: P<U>): P<T | U> {
return new P<T | U>((input) => {
const result = this.run(input);
if (result.success) {
return result;
}
return other.run(input);
});
}
}This can be easily chained to create parsers that can match multiple alternatives:
const prefixParser = P.string("Mr.").or(P.string("Ms.")).or(P.string("Dr."));Another useful combinator is seq, which takes an array of parsers and tries to apply them in sequence. The implementation uses TS function overloads to provider exact type inference for variadic parameters:
class P<T> {
static seq<T1, T2>(parsers: [P<T1>, P<T2>]): P<[T1, T2]>;
static seq<T1, T2, T3>(parsers: [P<T1>, P<T2>, P<T3>]): P<[T1, T2, T3]>;
static seq<T1, T2, T3, T4>(
parsers: [P<T1>, P<T2>, P<T3>, P<T4>],
): P<[T1, T2, T3, T4]>;
static seq<T1, T2, T3, T4, T5>(
parsers: [P<T1>, P<T2>, P<T3>, P<T4>, P<T5>],
): P<[T1, T2, T3, T4, T5]>;
static seq(parsers: P<unknown>[]): P<unknown[]> {
return new P<unknown[]>((input) => {
const values: unknown[] = [];
let currentInput = input;
for (const parser of parsers) {
const result = parser.run(currentInput);
if (!result.success) {
return { success: false };
}
values.push(result.value);
currentInput = result.remaining;
}
return { success: true, value: values, remaining: currentInput };
});
}
}This small set of building blocks is already enough to create some interesting parsers in a declarative manner, which would be much more cumbersome and error-prone than manually writing a procedural parser.
Example: HTTP Request Line Parser#
Let’s implement a simple parser for HTTP request lines, such as:
GET /index.html HTTP/3
POST /api/auth/email-code HTTP/2
DELETE /api/user/123 HTTP/1.1The technique described in this article allows tackling one sub-problem at a time, by defining small parsers and combining them into larger ones. Let’s start with the HTTP method parser (please ignore the missing methods for brevity):
const method = P.string("GET")
.or(P.string("POST"))
.or(P.string("PUT"))
.or(P.string("PATCH"))
.or(P.string("DELETE"));For the path, we could define a parser using small building blocks, such as:
const pathChar = P.char("/").or(P.char(".")).or(P.char("-")).or(P.char("_")).or(
P.char("a")
.or(P.char("b"))
.or(P.char("c"))
// ... add all valid characters
// or define a utility for character ranges/ dictionaries
.or(P.char("Z")),
);
// The `many` combinator is also not defined yet, but we'll get to it further in the series
const path = P.seq([P.char("/"), pathChar.many()]);But let’s be pragmatic and define a regex building block:
class P<T> {
static regex(regex: RegExp): P<string> {
return new P<string>((input) => {
const match = regex.exec(input.text.slice(input.index));
if (match && match.index === 0) {
const matchedString = match[0];
return {
success: true,
value: matchedString,
remaining: {
text: input.text,
index: input.index + matchedString.length,
},
};
}
return { success: false };
});
}
}and use the newly created building block it to define the path parser:
const path = P.regex(/\/[a-zA-Z0-9.-~/]*/);For the HTTP version, we can reuse the or and seq combinators:
const version = P.string("1.1").or(P.string("2")).or(P.string("3"));
const httpVersion = P.seq([P.string("HTTP/"), version]);Finally, we can combine all those parsers into the final requestLine parser:
const requestLine = P.seq([method, space, path, space, httpVersion]);Let’s give it a try!
const result = requestLine.parse("GET /index.html HTTP/3");
console.log(result.value); // ['GET', ' ', '/index.html', ' ', ['HTTP/', '3']]
const failResult = requestLine.parse("FETCH /index.html HTTP/3");
console.log(failResult.success); // false
As we can see, the parser successfully parsed a valid HTTP request line and returned the expected parts of the protocol header. When given an invalid input, it correctly indicated a failure. Still, the result structure is not very ergonomic, so let’s work towards mapping parser results to a more structured format.
Mapping parser results#
To improve the usability of our parsers, and in the future to build ASTs, we can define a map combinator that allows transforming the output of a parser into a more convenient format. If you’re familiar with functional programming and category theory, this is what you’d expect from a Functor.
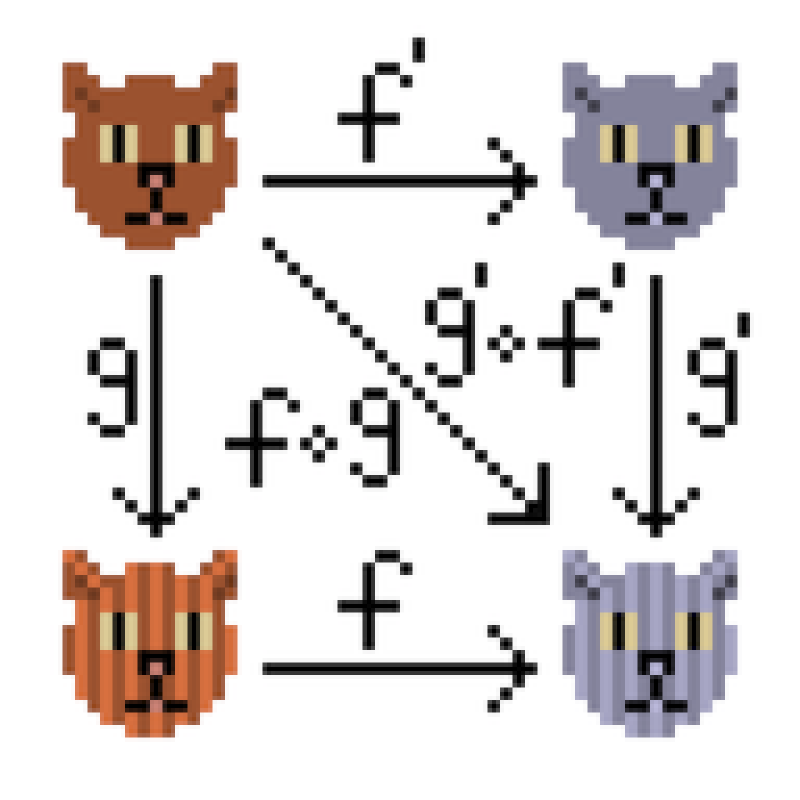
In simpler terms, it allows us to define the transformation for a P<T> parser to a P<U> parser, just like Javascript’s built-in Array.prototype.map method transforms an Array<T> into an Array<U>.
class P<T> {
map<U>(fn: (value: T) => U): P<U> {
return new P<U>((input) => {
const result = this.run(input);
if (result.success) {
return {
success: true,
value: fn(result.value),
remaining: result.remaining,
};
}
return { success: false };
});
}
}Let’s edit our requestLine parser (and sub-parsers) to return a more structured output:
-const httpVersion = P.seq([P.string("HTTP/"), version]);
+const httpVersion = P.seq([P.string("HTTP/"), version]).map(([, ver]) => ver);
-const requestLine = P.seq([method, space, path, space, httpVersion]);
+const requestLine = P.seq([method, space, path, space, httpVersion]).map(
+ ([method, , path, , version]) => ({ method, path, version }),
+);
Now, when we parse an HTTP request line, we’ll get a nicely structured object as the result:
const result = requestLine.parse("GET /index.html HTTP/3");
console.log(result.value); // { method: 'GET', path: '/index.html', version: '3' }
Also, observe that the type of result is correctly, and precisely inferred by TypeScript:
const result = requestLine.parse("GET /index.html HTTP/3");
// ^? ParseResult<{
// method: "GET" | "POST" | "PUT" | "PATCH" | "DELETE";
// path: string;
// version: "1.1" | "2" | "3";
// }>
Extra: TypeScript type inference#
This last bit is not related to parser combinators per se, but if you’re an upper-intermediate TypeScript developer, you might have seen similar approaches to type inference used in composition libraries such as zod or @sinclair/typebox, and that’s to leverage TypeScript’s powerful type system to extract the return types of a generic function/class, to avoid redundant type annotations:
type InferParser<U> = U extends P<infer T> ? T : never;This way, we can extract the output type of any parser P<T> by using InferParser<typeof myParser>, to keep our types DRY and consistent with the actual consumers.
Conclusion#
In this introductory article, we explored the concept of parser combinators, their advantages, and how to implement a simple parser combinator library in TypeScript. We also demonstrated how to use this library to create a parser for HTTP request lines.
Before getting to the next articles in the series, here are some challenges for you to try on your own:
- What other combinators do you think would be useful to implement? Can you think of a way to implement a parser that matches a positive number? Example:
42,3.14,0.001, - Can you implement a parser for ISO format date strings (or a subset of those)?
- Can you extend the HTTP request line parser to handle headers and body, effectively parsing a complete HTTP request?
- Can you implement error reporting in the parser combinator library, to provide more informative error messages when parsing fails?
The gist of the http request line parser can be found here.